-
BERT 구조와 Transformer Encoder 살펴보기[+] 인공지능 [+] 2021. 1. 23. 16:46
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT (Bidirectional Encoder Representations from Transformers)
자연어 처리를 공부하는 사람이라면 모르기 어려운 모델입니다.
혹자는 "우리는 BERT 의 시대에 살고있다"는 표현을 사용하기도 합니다.
BERT 모델의 논문 부제로 Pre-train, Bidirectional, Language Understanding, 또 BERT의 풀네임 중에 Encoder, Transformers, Representations 라는 키워드가 사용되는데 이는 BERT의 성격을 잘 포함하고 있다고 생각합니다.
우선 BERT는 Language Representation 모델입니다.
특정한 하나의 테스크를 해결하기 위해 고안된 모델이 아닌, 언어 전반을 이해하고, 이를 백터로 표현하는데 특화된 모델입니다. 언어를 잘 이해하는데 특화된 이 모델은 Fine tuning을 걸쳐 DownStream task에 적용됩니다.

https://arxiv.org/abs/1810.04805 당시 BERT모델이 발표되었을 당시 GLUE, SQuAD 등 11개의 NLP task 에서 SOTA를 갱신하였습니다.
이는 BERT가 얼마나 Language Representation에 강력한지를 방증합니다.
BERT는 Bidirectional 모델입니다.
이를 이해하기 위해 GPT 모델을 먼저 살펴봅시다.
GPT 모델은 Transformer Decoder 구조가 겹겹이 쌓인 형태로 이루어져 있습니다.
또한 Decoder 블록은 단방향으로 동작하며, 문장을 생성하는 task에 높은 성능을 발합니다.

Transformer Decoder - Causal Attention 위의 The cat sat on the mat 라는 문장을 예로 들자면,
Sat 이라는 벡터를 예측할때 앞서 입력된 The, Cat 벡터가 사용됩니다.
Sat 백터를 예측하기 위해 on, the, mat 토큰을 사용하지 못하게끔 마스킹을 추가합니다.
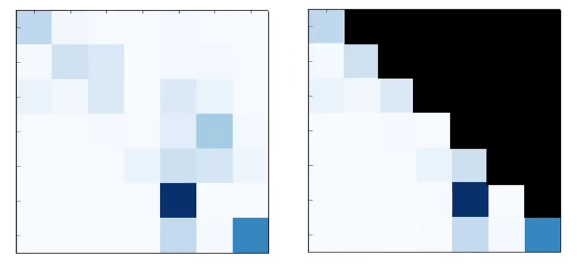
왼쪽 - Encoder Attention / 오른쪽 - Decoder Attention 이전 입력된 The, Cat 토큰에 의존하여 이어질 단어를 예측합니다. 이러한 형태의 Attention 구조를 Causal Attention 이라 합니다.
The, Cat 토큰을 통해 Sat 토큰을 예측하고, 또 The, Cat, Sat 토큰을 사용하여 on 토큰을 예측하는 방식으로 진행됩니다.
(이러한 방식을 Auto Regressive라 합니다)
반면 Encoder 블록은 task를 수행하기 위해 입력 문장의 모든 토큰이 사용됩니다. 이 형태의 Attention 구조를 self attention 이라 합니다.

Transformer Encoder - Self-Attention BERT 모델은 이런 Transformer Encoder 블록이 겹겹이 쌓인 형태로 구성되어 있습니다.
Self Attention 구조 내부에서는 내적 연산을 통하여 Attention 백터를 생성합니다.
이 Attention 벡터는 각각의 단어가 서로 어떤 연관성을 갖는지를 내포합니다.
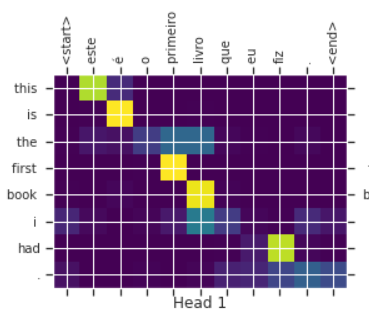
Attention map 위의 사진은 영어-포르투갈 번역 모델입니다
Attention map에서 알 수 있듯이, This 라는 단어는 este라는 단어와 강하게 반응하는데,
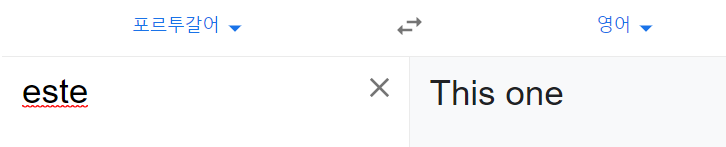
실제로 Este는 This one 이라는 뜻을 갖고 있다고 합니다.
this 토큰에 더 강한 가중치를 부여하여 este를 예측할때 다른 토큰보다 this 토큰을 더 집중하여 예측합니다.
BERT는 Pre-trained 모델입니다.
하나에 모델을 구현한 후 Question Answering task를 수행하고자 한다면, 가장 좋은 방법은 대량의 QA 데이터 셋을 구한 후 모델에 학습시키는 방법일 것입니다.
하지만 Label이 된 데이터를 구하기는 어려운 법이고, 직접 만들어 내기엔 시간과 비용이 상당히 많이 소요됩니다.
위 문제를 해결하기 위해, 데이터를 공수하기 쉬운 다른 자연어 처리 문제를 학습시킨 후, 어느정도 가중치가 업데이트된 상태에서 QA와 같은 특수한 task 에 적용시킵니다.
이를 사전학습(pre-train)이라 합니다.
쉬운 이해를 위해 예를 들어 보자면,
우리는 수능 영어에서 "주제 파악"문제를 잘 풀고자합니다.
하지만 주제 파악 문제는 만들기 어렵고, 구하기도 어려운 까닭에 주제 파악 문제만 들입다 풀어서 실력을 올리기는 어렵습니다.
그래서 "빈칸 추론" 문제와 "순서 배열" 문제를 잔뜩 풀어서 영어 전반을 잘 이해하고 있는 상태로 충분히 끌어올려 놓고, 주제 파악 문제를 집중적으로 학습합니다.
"빈칸 추론" 문제와 "순서 배열"문제는 얼마든지 만들어 낼수 있습니다.
빈칸 추론 문제는 별도의 레이블링 작업 없이 평문에서 특정 단어를 하나 지운 후, 그 단어를 갖고 있으면, 쉽게 정답 클래스와 입력 클래스를 만들어 낼 수 있습니다.

https://www.youtube.com/watch?v=1IwHZ_4uPK0&list=PLsXisDblbLJ8msozFyA8o2zf3zfbORHWd&index=2 순서 배열 문제에서도 동일합니다. 문단 형식의 자연어는 쉽게 공수할 수 있습니다.
문장 단위로 분할 한 후 해당 문장 뒤에 이어질 문장을, 실제 뒤에 이어진 문장(혹은 엉뚱한 문장)을 주며 두 문장이 이어진 문장인지 아닌지를 판단하게 끔 하는 분류 작업을 수행합니다.
위의 빈칸추론 문제는 NLP 에서 MLM(Masked Language Model)
순서 배열 문제는 NSP(Next Sentence Prediction) 이라 합니다.
BERT 논문에서도 위의 두가지 task를 수행하여 pre-train을 진행합니다.
NSP task 를 수행하기 위해선 두 문장이 한 쌍이 되어 입력으로 제공되어야 합니다.
그런 까닭에 Transformer Encoder 구조와 BERT의 input representation이 사뭇 다릅니다.
Input Representation

https://arxiv.org/pdf/1810.04805.pdf Token Embedding
일반적인 Token Embedding 입니다. Word Piece 임베딩 방식을 사용합니다. 길이가 긴 문장이나, 빈출도가 낮은 문장은 분절하여 sub-word 처리 합니다.
Segment Embedding
위의 사진에서는 my dog is cute 와 he likes play ing 이 두 문장이 한 쌍이 되어 입력으로 제공됩니다.
이를 구분할 수 있는 벡터로서, Segment Embedding 벡터를 생성한 후 적용합니다.
Position Embedding
이전까지 Transformer 구조에서는 주기 함수를 이용한 Position Encoding 방식이 사용되었습니다. 순환 신경망 구조를 탈피한 까닭에 각 자리에 위치한 토큰들의 위치 정보를 포함하기 위함입니다.
Position Encoding 방식은 위치 정보를 포함하는데에 탁월하지만, 다른 토큰들의 위치 정보들과 반응하지 못합니다.
BERT모델은 Position Embedding 방식을 고안하여 적용되었습니다.
References
- www.youtube.com/watch?v=KQfvEg-fGMw&t=2237s
- keep-steady.tistory.com/19
- arxiv.org/abs/2010.04903
- hwiyong.tistory.com/392
- www.tensorflow.org/tutorials/text/transformer
- www.youtube.com/watch?v=1IwHZ_4uPK0&list=PLsXisDblbLJ8msozFyA8o2zf3zfbORHWd&index=2
- medium.com/platfarm/%EC%96%B4%ED%85%90%EC%85%98-%EB%A9%94%EC%BB%A4%EB%8B%88%EC%A6%98%EA
- docs.likejazz.com/bert/
- dongchans.github.io/2019/119/
- arxiv.org/abs/1901.02646
'[+] 인공지능 [+]' 카테고리의 다른 글
[논문 리뷰] ELMo : Deep contextualized word representations (0) 2021.05.11 Text Summarization : Models (0) 2021.03.07 Text Summarization: Overview and Metric (0) 2021.02.20 CNN 개요와 흐름 (0) 2020.12.13 인공 신경망의 역사 (0) 2020.11.25